How to create fast queries with Loki’s LogQL to filter terabytes of logs in seconds
LogQL, the Loki query language, is heavily inspired by Prometheus PromQL. However, when it comes to filtering logs and finding the needle in the haystack, the query language is very specific to Loki. In this article we’ll give you all the tips to create fast filter queries that can filter terabytes of data in seconds.
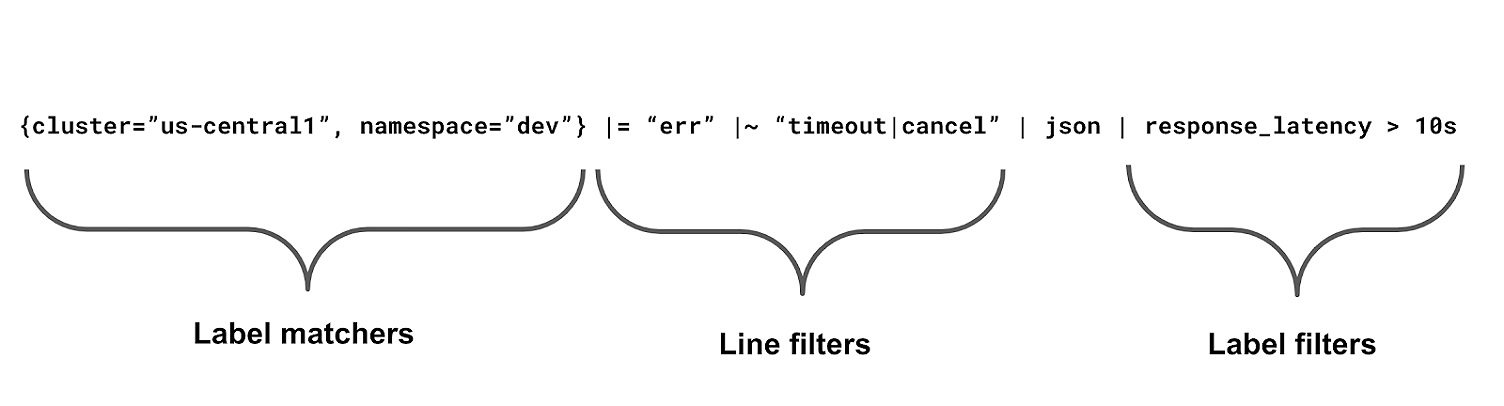
In Loki there are three types of filters that you can use:
Label matchers
Label matchers are your first line of defense, the best way to drastically reduce the amount of logs (e.g., from 100TB to 1TB) you’re searching for. Of course this means you need to have good label hygiene with your agent: Basically, labels should define your workload (cluster, namespace, and container are good ones to stick to) so that you can slice the data on multiple different dimensions. For example:
- My application across all clusters
- My application in the dev namespace across all clusters
- My prod namespace
- Etc.
The rule of thumb is: You need at least one equality matcher (e.g., {cluster="us-central1"}). Otherwise you’ll have to pull the whole index data. There’s one exception, though: You can have a single regex matcher if it includes one or more literals, such as {container=~"promtail|agent"}, because Loki can optimize this away. Here are some good and bad examples:
Good:
{cluster="us-central1"}
{container="istio"}
{cluster="us-central1", container=~"agent|promtail"}
Bad:
{job=~".*/queue"}
{namespace!~"dev-.*"}
Line filters
Line filters are your second best friend, as they are super fast. They allow you to filter logs that contain (|=) or do not contain (!=) strings, and you can also use RE2 regexes to match (|~) or not match (!~) a pattern. It’s not mandatory, but you should have them right after label matchers.
You can chain several of those filters, but be aware that the order matters a lot here. You want the ones that filter the most first, then you can use regexes, which are slower than equality and inequality but will be applied on fewer lines. It’s perfectly fine to run equality and inequality on millions of lines, but that will likely be slow with regexes.
Again there’s an exception: |~ "error|fatal" can be optimized away by Loki and is in fact error or fatal, so no regexes will be executed.
A good way to go is to start by adding a filter that matches what you’re looking for, for instance, |= "err". Execute that, then add more and more inequalities to remove what you don’t want, until you end up with something like |= "err" != "timeout" != "cancelled" |~ "failed.*" != "memcached". Now if you realize most of your errors come from memcached, then move it to the first position: != "memcached" |= "err" != "timeout" != "cancelled" |~ "failed.*". This way, subsequent filters will be executed fewer times.
Line filters are also good for finding an IP, a trace ID, an identifier in general. So {namespace="prod"} |= "traceID=2e2er8923100" is a good query. Of course, if you want all logs for this trace that match a certain regex, add |~ "/api/v.+/query" after the ID filter, so that it’s not executed for every single line in your prod namespace.
Label filters
Label filters provide more complex comparisons (duration, numerical, etc.), but they usually require extracting labels first and then converting the label value into another type. Meaning they usually are the slowest, so you should use them last.
OK, little secret here, you can actually use label filters without extracting labels (with parsers such as
| jsonor| logfmt). Label filters also work on indexed labels. So for example,{job="ingress/nginx"} | status_code >= 400 and cluster="us-central2"works fine, but what you really should be asking yourself is whether you need that status_code as an index label. Generally no, you shouldn’t, but you might consider extracting status_code as a label to break up high-volume streams (more than a thousand lines per second) into separate streams.
While the | json and | logfmt parsers are fast, the | regex one is pretty slow. This is why when using parser, I’m always preceding it with a line filter. For example, in my Go applications (including Loki), all my logs are attached with the file and the line number (here caller=metrics.go:83):
level=info ts=2020-12-07T21:03:22.885781801Z caller=metrics.go:83 org_id=29 traceID=4078dafcbc079822 latency=slow query="{cluster=\"ops-tools1\",job=\"loki-ops/querier\"} != \"logging.go\" != \"metrics.go\" |= \"recover\"" query_type=filter range_type=range length=168h0m1s step=5m0s duration=54.82511258s status=200 throughput=8.3GB total_bytes=454GBSo when I want to filter slow requests, I use the file and line that logs the latency as a line filter, then parse it and compare it with a label filter.
{namespace="loki-ops",container="query-frontend"} |= "caller=metrics.go:83" | logfmt | throughput > 1GB and duration > 10s and org_id=29Conclusion
These three filters (label matchers, line filters, and label filters) are like a pipeline that will process your logs step by step. You should try to reduce as much as possible at each step, since each subsequent step is more likely to be slower to execute for each line.
I hope you enjoyed my tips to write fast filter queries in Loki. Make sure to read the full LogQL documentation on our website, and let me know what other how-tos you might want me to cover next!
Try out Loki by installing it yourself or get started in minutes with Grafana Cloud. We’ve just announced new free and paid Grafana Cloud plans to suit every use case — sign up for free now.