

How to switch Cortex from chunks to blocks storage (and why you won’t look back)
If you’ve been following the blog updates on the development of Cortex – the long-term distributed storage for Prometheus – you surely noticed the recent release of Cortex 1.4, which focuses on making support for “blocks engine” production-ready. Marco Pracucci has already written about the blocks support in Cortex, how it reduces operational complexity for running Prometheus at massive scale, and why Grafana Labs has invested in all of that work. So in this post, I’m going to focus on an important issue for long-time Cortex users:
If you’re already running Cortex with previous “chunks” storage, how do you actually switch to using blocks?
There’s a two-part answer to that question. The first, which I call “migration,” is about reconfiguring a live production cluster to start storing new data into blocks. The second, which I’ll refer to as “conversion” will address what to do with existing data.
Migrating a live cluster from chunks to blocks storage
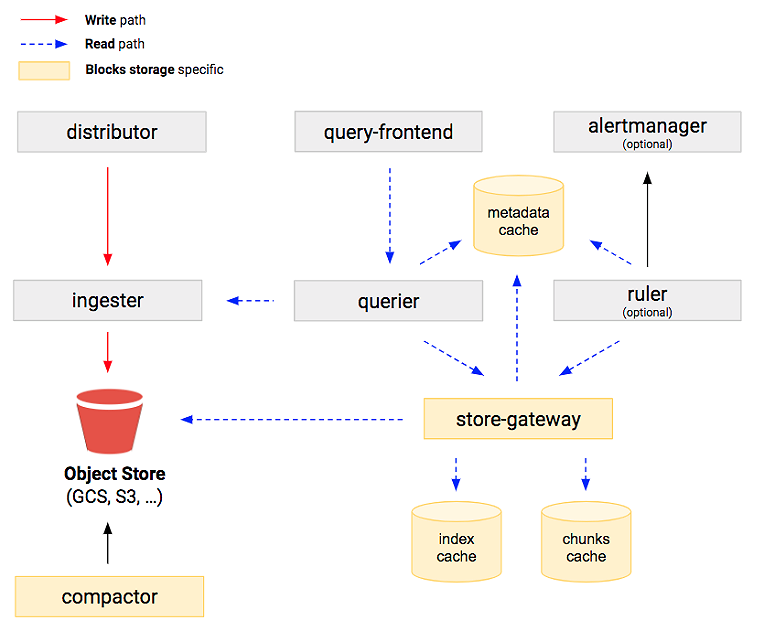
The idea behind cluster migration is simple, really: You reconfigure the write path to store data into blocks, and reconfigure the read path to query those blocks as well as existing chunks data.
To make it all work, a couple of missing features needed to be added to Cortex, and a couple of bugs had to be fixed in both paths.
Now, Cortex has the ability to query both storages at the same time and merge the results. It can also properly deal with and merge data from both chunks-based and block-based ingesters, which is a scenario that happens when querying Cortex during the migration process.
We’ve developed a procedure to perform this migration, and have already successfully migrated several of the production clusters that are powering our Hosted Metrics service.
Converting long-term storage from chunks to blocks
So what do you do about old data? That’s where the conversion process comes into play.
Cortex OSS now features a suite of tools for doing chunks to blocks conversions. We call this suite blocksconvert and it consists of the following:
- Scanner, which reads the Cortex index used by chunks storage and generates plans. Each plan contains a list of series and chunk IDs that are to be stored into a single block. Since we use 1-day blocks, each plan covers one day of data for a single user.
- Builder, which takes a single plan and downloads chunks referenced from it, then builds a block which gets uploaded to long-term storage. Builder then repeats the process until there are no more plans available. Multiple Builders can run to make the conversion process faster.
- Scheduler, which is responsible for handing out the plans that builders work on.
These tools work together to convert existing chunks to blocks.
During our conversions, we have calculated that the blocks use between 20 and 60 percent less space than chunks storage.
There are several factors that contribute to this reduction:
- Chunks produced by different ingesters may contain replicated samples (even if chunks synchronization is enabled), but when they’re converted to block, such samples are deduplicated.
- Each chunk for a single series contains a header with the series labels set, and this uses a significant portion of the entire chunks size. When converting to block, the set of labels for each series is only written in the block’s index once.
- Block index uses string deduplication to minimize the index size.
Builder has been optimized to handle a large number of series inside the single block, and it’s only limited by the free space on the disk used for building the block.
Rewarding results
Here at Grafana Labs, we’ve successfully migrated multiple production clusters to use Cortex’s new blocks storage engine with no downtime or interruptions, and with no degradation in query performance during the migration.
In fact, here’s a look at some numbers from conversions on our infrastructure:
- Scanning index table stored in BigTable runs about 100 GiB/hour and generates plan files of about 10 percent of size of index table
- It takes about 20 minutes to build a single block with one day of samples for 1M series
- Such block for 1M series will use about 4GB of disk space
So if you have Cortex running on chunks storage today, why not give blocks a try?

![[KubeCon + CloudNativeCon EU recap] Getting some Thanos into Cortex while scaling Prometheus](/static/assets/img/blog/kubeconeucortexblocksstorage6.jpg?w=764)