

New in Grafana 7.2: $__rate_interval for Prometheus rate queries that just work
What range should I use with rate()? That’s not only the title of a true classic among the many useful Robust Perception blog posts; it’s also one of the most frequently asked questions when it comes to PromQL, the Prometheus query language. I made it the main topic of my talk at GrafanaCONline 2020, which I invite you to watch if you haven’t already.
Let’s break the good news first: Grafana 7.2, released only last Wednesday, introduced a new variable called $__rate_interval. In most cases of graphing rate queries, it will be the right choice to simply use $__rate_interval as the range.
Let’s dive a bit deeper into this topic to understand how $__rate_interval manages to pick the right range.
In both my talk and in RP’s blog post, you’ll notice two important takeaways:
- The range in a
ratequery should be at least four times the scrape interval. - For graphing with Grafana, the variable
$__intervalis really useful to specify the range in aratequery.
So let’s create a Grafana panel with a typical rate query, for example, to find out how many samples per second our Prometheus server ingests (I love using Prometheus to monitor Prometheus):
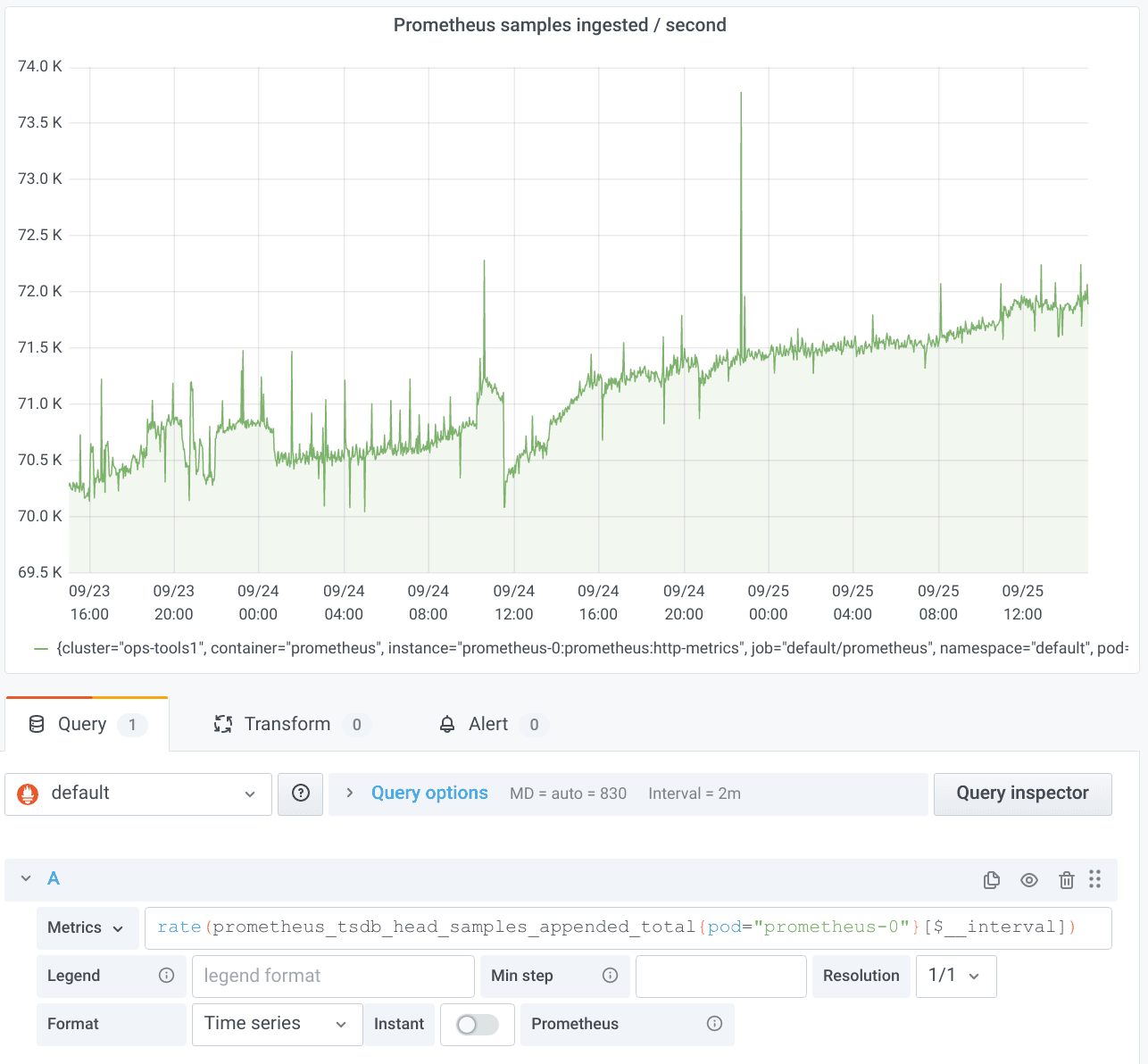
That worked just fine. But what happens if we zoom in a lot? Let’s go from the two days above to just one hour.
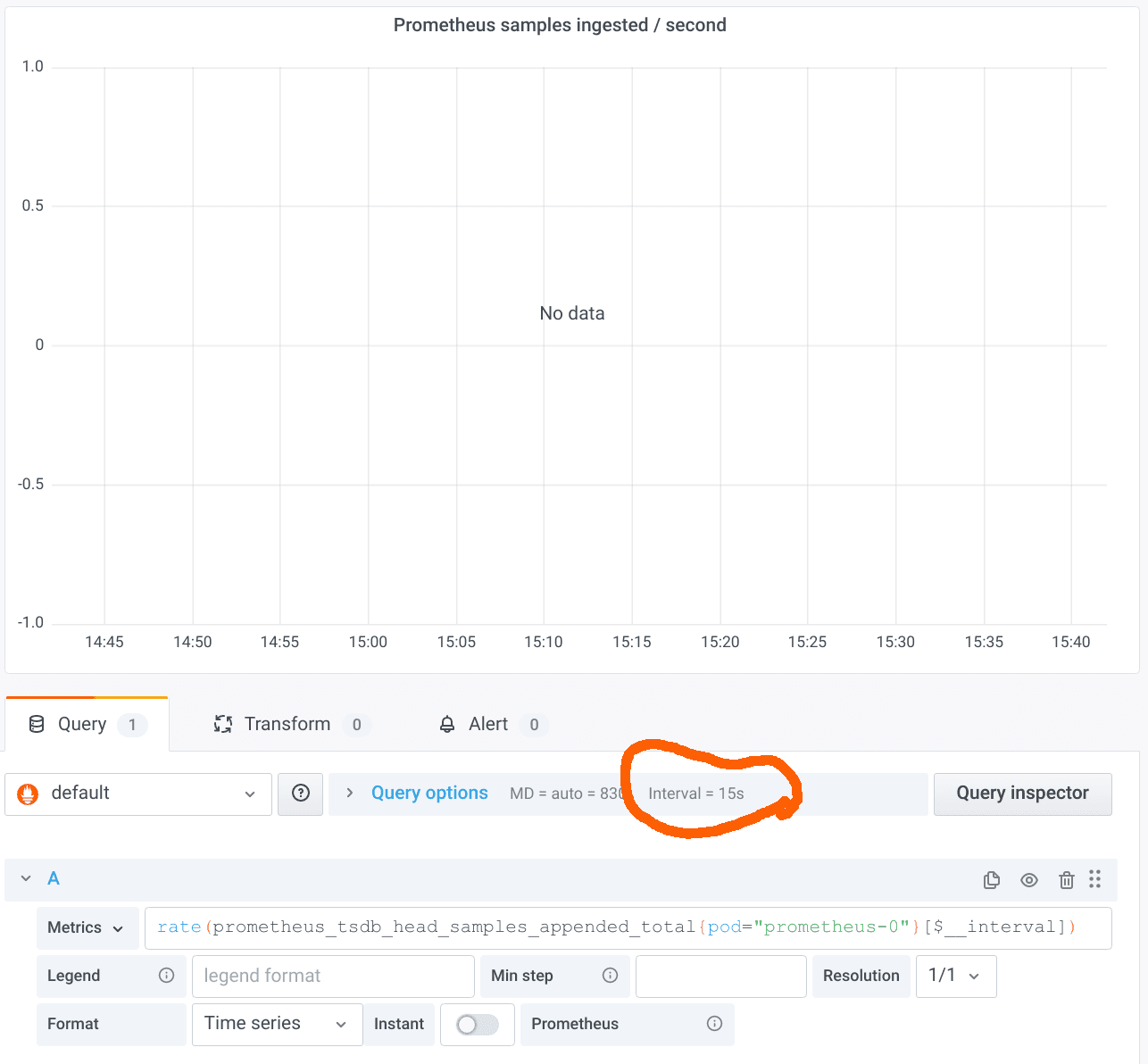
The result is very disappointing: “No data”! The reason is that we have breached the first of the takeaways listed above. The $__interval variable expands to the duration between two data points in the graph. Grafana helpfully tells us about the value in the panel editor, as marked in the screenshot above. As you can see, the interval is only 15s. Our Prometheus server is configured with a scrape interval of 15s, so we should use a range of at least 1m in the rate query. But we are using only 15s in this case, so the range selector will just cover one sample in most cases, which is not enough to calculate the rate.
Let’s fix this situation by setting a Min step of four times the scrape interval, i.e. 1m:
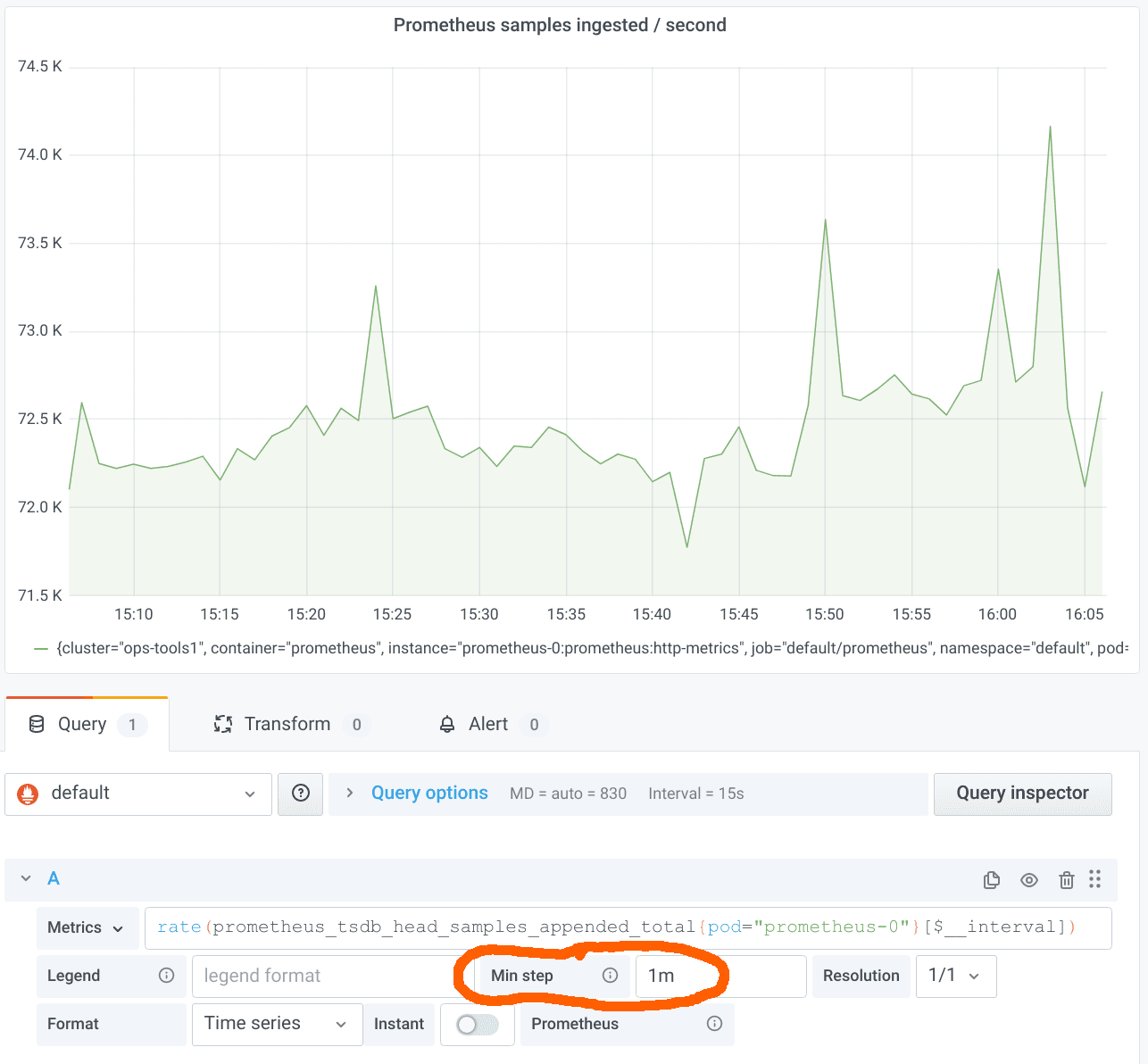
This approach is following the recommended best practice so far. It works quite well, but it has two issues:
- It requires you to fill in a Min step in every panel that is using
ratequeries. - It limits the resolution at which Grafana requests the evaluation results from Prometheus. One might argue that it doesn’t make a lot of sense to request a
rateover 1m at a resolution higher than one data point per minute. A higher resolution essentially results in a moving average. But that’s what some users want.
The new $__rate_interval variable addresses both of the issues above. Let’s remove the Min step entry again and change $__interval to $__rate_interval:
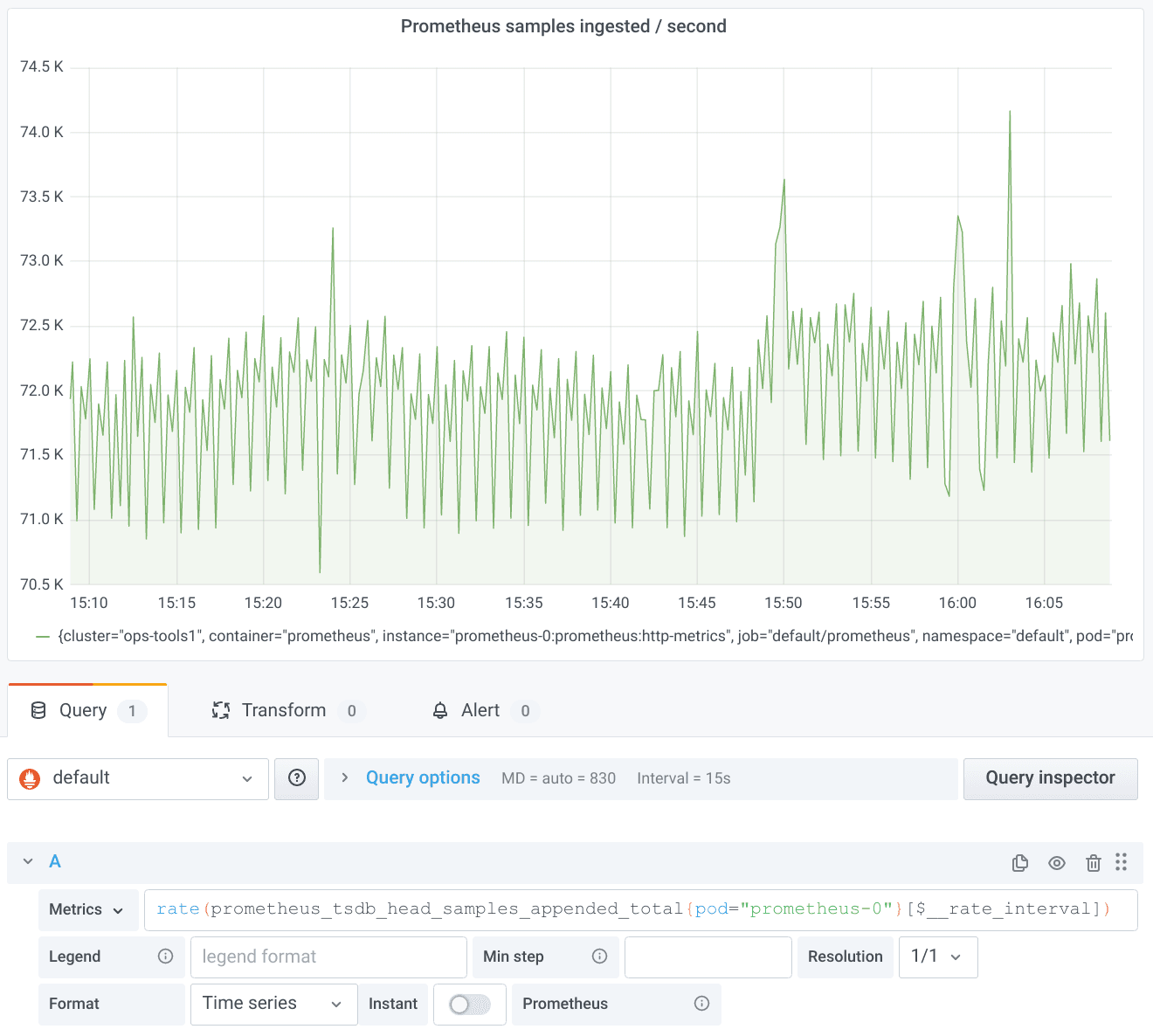
Now all looks great again. The moving average effect described above even reveals some higher resolution structure not visible before. (Pro tip: If you want the smoother graph back as before, don’t despair. Just open the Query options and set a Min interval of 1m.)
So what’s the magic behind $__rate_interval? It is simply guaranteed to be at least four times the scrape interval, no matter what. But how does it know what the scrape interval is? That’s actually a very good question, because Prometheus itself only knows the currently configured scrape interval and doesn’t store the scrape interval used for historical data anywhere. (Perhaps that will change in the future, but that’s a story for another day.) Grafana can only rely on the scrape interval as configured in its Prometheus data source. If you open the settings of a Prometheus data source, you’ll find the Scrape interval field in the lower half:
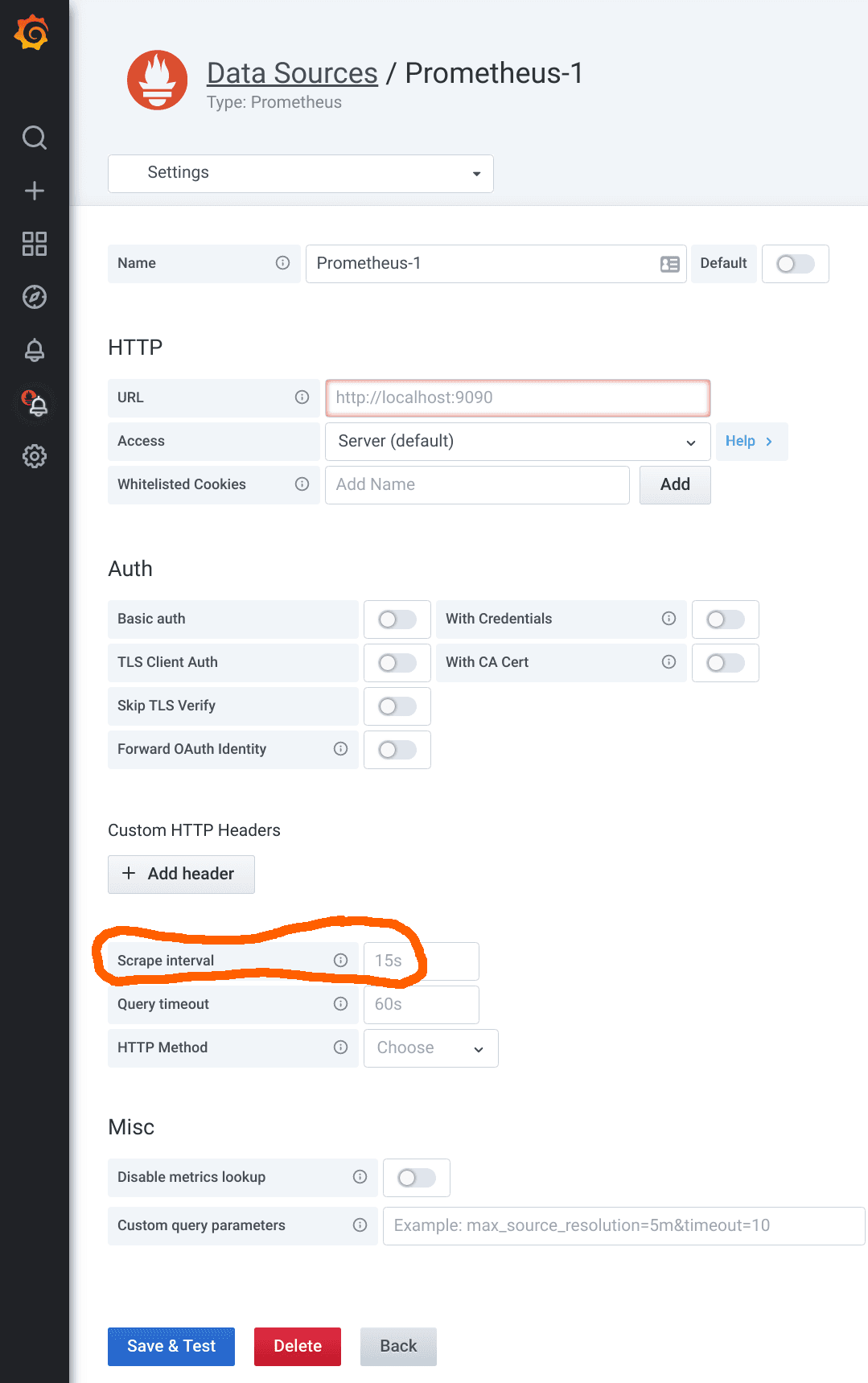
It is recommended you use the same scrape interval throughout your organization. If you do that, it’s easy to just fill it in here. (The default value is 15s, by the way.) But what to do if you have the odd metric that has been scraped with a different scrape interval? In that case, use the Min step field to enter the special scrape interval, and everything will just work again. (Pro tip: Note that the Min interval setting in the Query options does not change the scrape interval used for the $__rate_interval calculation. You can use it to get lower-resolution graphs without changing the assumed scrape interval.)
But that’s not all. $__rate_interval solves yet another problem. If you look at a slowly moving counter, you can sometimes observe a weird effect. Let’s take prometheus_tsdb_head_truncations_total as yet another metric Prometheus exposes about itself. Head truncations in Prometheus happen every two hours, as can be nicely seen by graphing the raw counter:
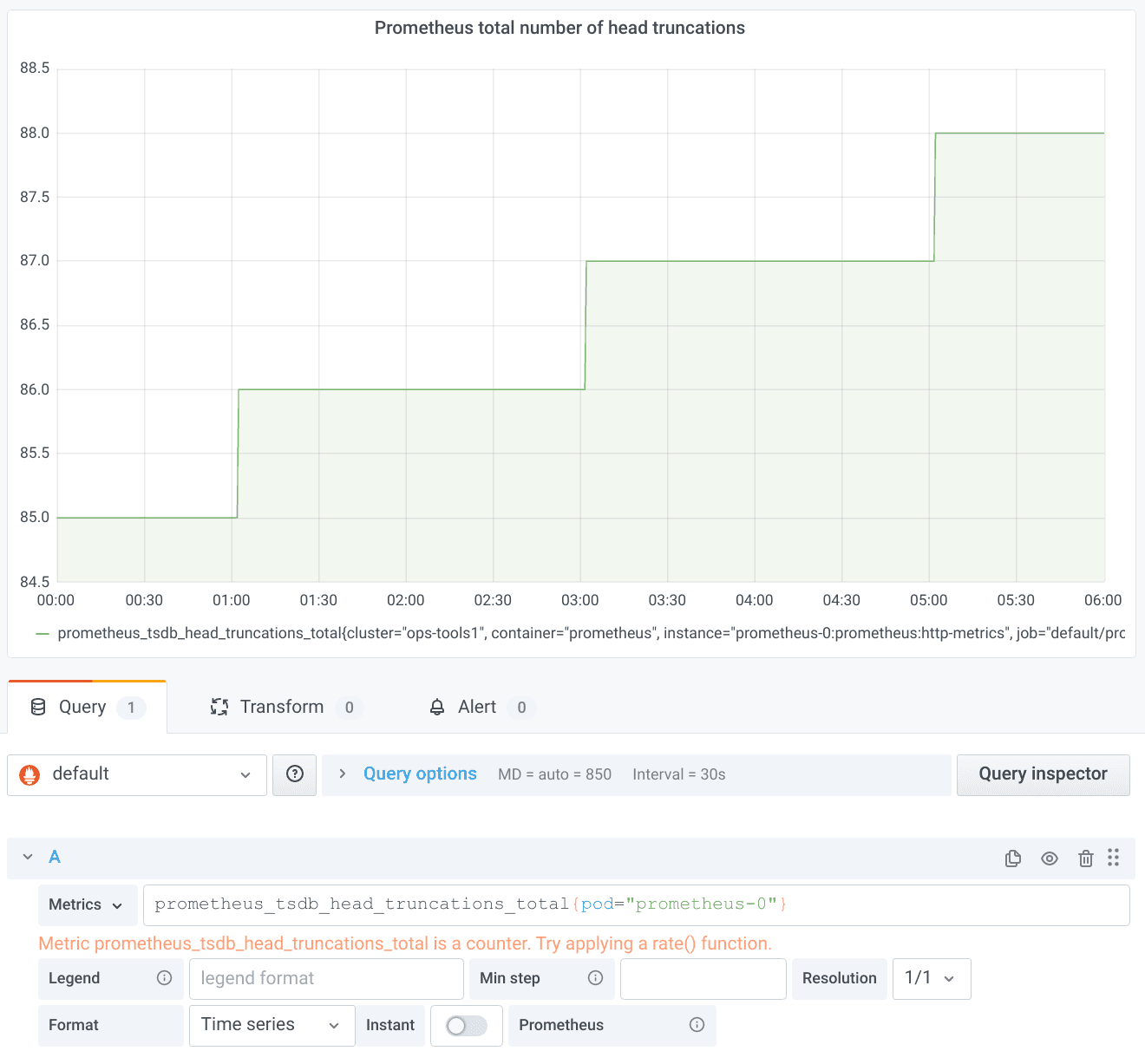
Since we are looking at a quite long time range, the old $__interval should just work out of the box. Let’s try it:
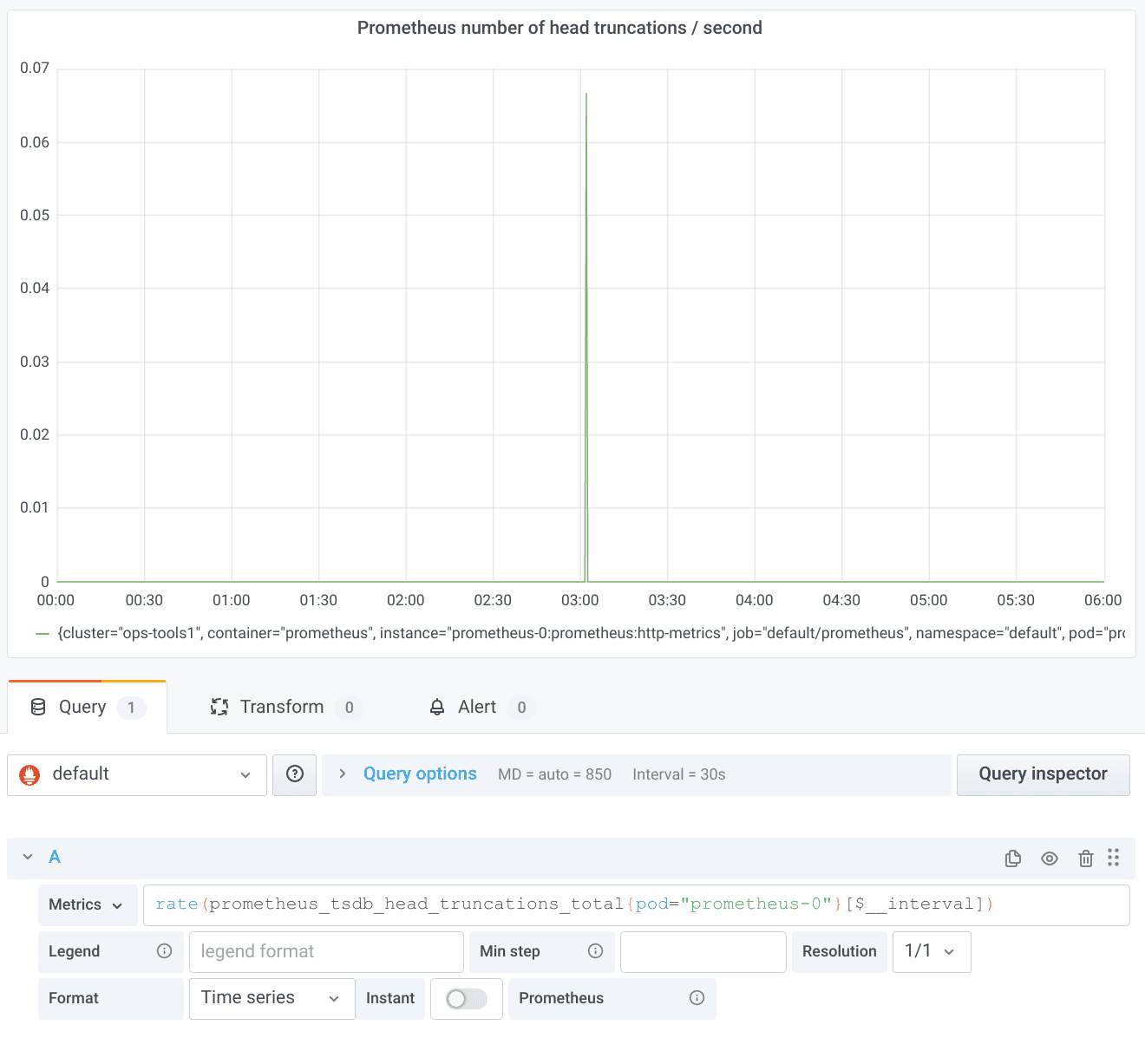
This is surprising. We would have expected one peak in the rate every two hours. The reason for the missing peaks is subtle: A range selector in PromQL only looks at samples strictly within the specified range. With $__interval, the ranges are perfectly aligned; i.e., the end of the range for one data point is the beginning of the range of the next data point. That means, however, that the increase between the last sample in one range and the first sample in the next range is never taken into account by any of the rate calculations. With a bit of bad luck, just the one important counter increase you are interested in gets swallowed by this effect. At the end of my aforementioned talk, you can enjoy a more detailed explanation of the whole problem, for which, as promised in the talk, the new $__rate_interval once more provides a solution:
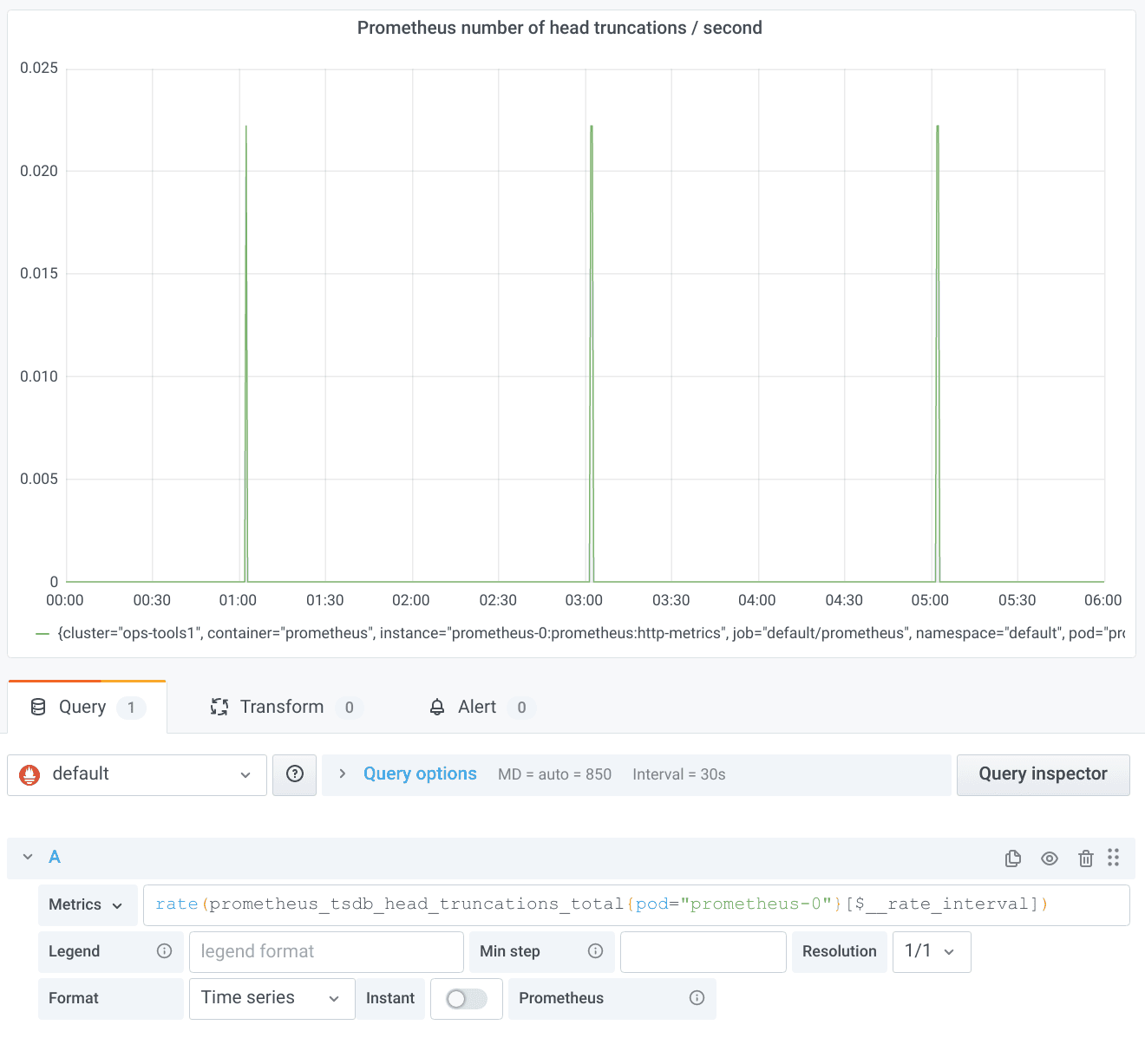
Again, this magic turns out to be quite simple on closer inspection. $__rate_interval extends the usual $__interval by one scrape interval so that the ranges overlap just enough to ensure complete coverage of all counter increases. (Note for pros: This only works if the scrapes have happened at the intended points in time. The more jitter there is, the more likely you run into problems again. There is unfortunately no single best way to deal with delayed or missing scrapes. This topic is once more a story for another day…)
The wonderful Grafana documentation summarizes the whole content of this blog post very concisely: “The $__rate_interval variable is […] defined as max( $__interval + Scrape interval, 4 * Scrape interval), where Scrape interval is the Min step setting […], if any is set, and otherwise the Scrape interval as set in the Prometheus data source (but ignoring any Min interval setting […]).”
The good thing about $__rate_interval: Even if you haven’t fully understood every single aspect of it, in most cases it should “just work” for you. If you still run into weird problems, well, then you have hopefully bookmarked this blog post to return to it and deepen your understanding.

