
How Loki Reduces Log Storage
Several months ago, Bryan Boreham introduced a few changes to Cortex that massively reduced its storage requirements. The changes were quite simple and altogether had a nice benefit of using almost 3x less data storage than prior versions. Since Loki shares a lot of code with Cortex, could we use these ideas to the same effect? (Spoiler alert: Yes, we can!)
Shared Heritage: Loki and Cortex
Loki is our solution for storing a huge amount of logs and making them searchable. Loki is built on top of Cortex, a horizontally scalable Prometheus implementation and CNCF project, and they both share the same architecture.
In both Cortex and Loki, the ingester component is responsible for collecting the input – metric samples in Cortex and log lines in Loki – and generating compressed files called “chunks” that store the information. To avoid losing data, we replicate writes to multiple ingesters (typically three in Grafana Labs’ production) and have them process the same input, storing it afterwards. If each ingester generates a chunk and stores it individually, generally it means that we store the same input three times.
Boreham realized that with some care, Cortex can be changed to increase the chance that ingesters generate exactly the same chunks for the same input. When this happens, the first ingester that uploads the new chunk to the storage will proceed as usual, but two other ingesters (when using three replicas) will discover that the chunk is already uploaded and will skip the upload.
What tricks were used to achieve this? One problem that Boreham has discovered and fixed was that chunks from different ingesters had labels written in a different order. By simply sorting the labels before writing the chunk, this problem was quickly fixed.
Another simple change to avoid duplicate uploads was to use Memcached to store the IDs of recently uploaded chunks. When an ingester generates a new chunk, it assigns an ID based on the content of the chunk. It can then check the Memcached server to see if this ID was already uploaded, and if it was, there is no need to upload the chunk again, which would just overwrite the existing chunk with the same ID and content.
The third change – and most important for long-term series – was to force Cortex to split the data into chunks at the same moment. Cortex uses a six-hour window when storing data; if the incoming sample is older than six hours from the oldest sample in memory for a given time series, then Cortex will “cut the chunk” (take existing data and generate a chunk) before accepting the new sample. The problem here was alignment: Since ingesters typically start at different times, the oldest sample is different between them.
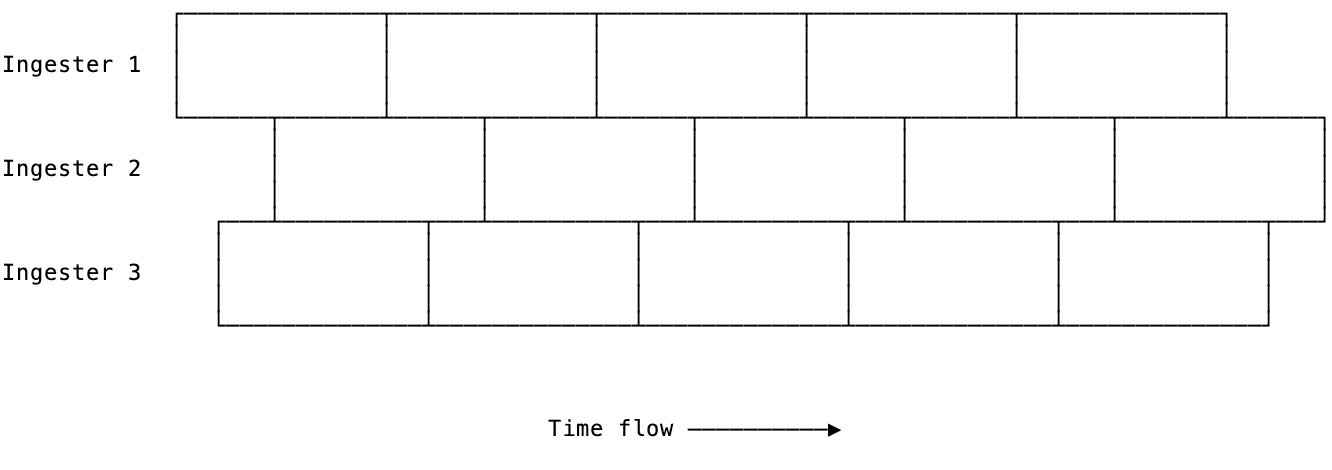
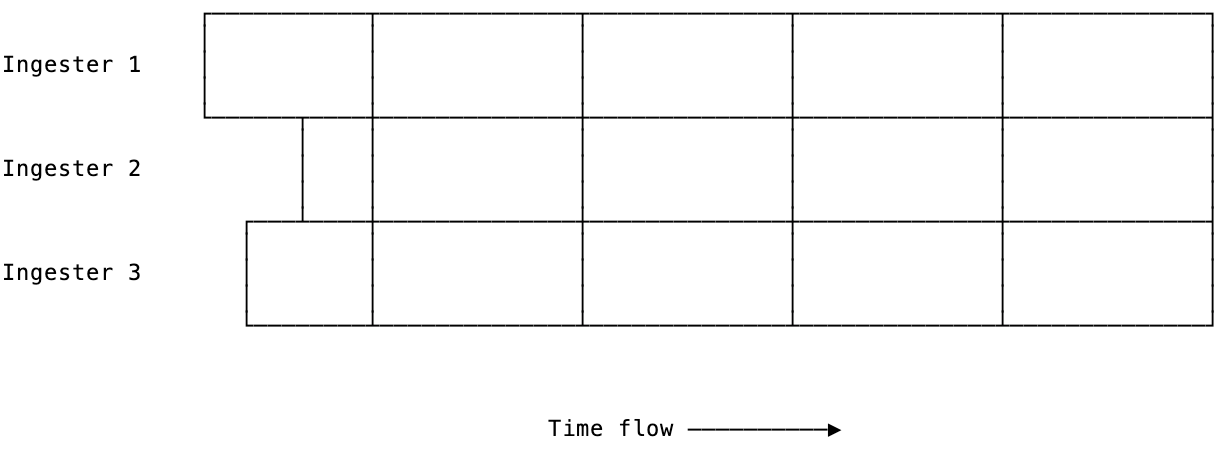
What Boreham did was to change the chunk-cutting decision for all ingesters, no matter if the chunk already covered a six-hour period or not. First chunks after restart are typically smaller than six hours, but subsequent chunks will be six hours long. More importantly, chunks generated on different ingesters will contain exactly the same data.
Applying Lessons to Loki
As Loki uses a lot of Cortex code, it automatically received label-sorting and memcached-based check code benefits. But since Loki stores log lines instead of metric samples, it uses a different way of cutting chunks. Instead of storing data in a fixed time window, Loki targets configurable chunk size – for example, chunks containing 2 MiB of original data. That means that Loki cannot use the time-based, chunk-cutting idea directly because it could potentially lead to chunks that are too large.
What if we combine time-based chunk cutting with required minimum utilization? Say we try to cut the chunk every 10 minutes, but only if the current chunk is utilized at least 30 percent. If it isn’t, we don’t cut the chunk. This idea should increase the chance that different ingesters decide to cut the chunk at the same moment, and from that point on, if everything goes well, they will generate the same chunks.
And that is exactly what we did in Loki 1.3. After deploying this change to our internal cluster, we didn’t initially see any obvious benefit. Chunks were cut at the same time, but somehow they contained different data and had different checksums!
After inspecting the chunks with our new chunk inspection tool, we discovered that they do indeed contain the same data or log lines, but after compression, the outputs were slightly different. This is most likely the result of Loki trying to reuse the writer instances in order to save on buffer allocations. This bug has been reported to the relevant library.

Above, we can see three chunks with the same start and end times, but they are slightly different sizes. The last column shows how much time overlap there is with previous chunks.
As Loki now has configurable chunk compression algorithms, we switched to a different algorithm (Snappy) and saw the results immediately:

Above, we can see an example where three different ingesters cut the chunk exactly at the same time (09:44:11.680 UTC). From that point on, there is only one chunk per given time range.
The Benefits
As we can see, this already has benefits by Loki using less storage than before. Previously we stored three copies of the same data. Now we store approximately 1.2 copies. (There is no concrete metric for this; this value is based purely on inspecting chunks for certain queries and seeing how much overlap there is between individual chunks.)
This not only helps to keep storage costs down. It also helps in searches since Loki always needs to fetch all chunks for selected series when running the search. Fewer chunks equals less data which means faster searches! This, in turn, helps caches since Loki also stores fetched data in Memcached servers to avoid downloading the same chunks again and again for similar or repeated queries.
Unfortunately, there are some edge cases that still aren’t solved by this simple algorithm described above. We use a 15-minute sync interval and 20 percent minimum utilization. So if an ingester tries to cut the chunk every 15 minutes, but if the chunk is underutilized (it has less than 20 percent of configured chunk size), we keep using it. If ingesters don’t get into sync, they keep writing slightly different chunks for the same data, thus never seeing deduplication benefits.


Example: Two ingesters writing chunks containing 30 minutes of data. They are 15 minutes shifted.
This is visible with idle series, but it can also happen with busy series with a lot of logs. Busy series would benefit from deduplication the most but may not get into a sync at all.
Another problem is that sometimes ingesters get into a sync, but a couple of minutes later, they desynchronize again. When another 15-minute sync point occurs, they get into sync, but then desynchronize again. We see partial success, but it would be nice to find out why they desynchronize – and if we can fix it. We need to do some investigation here.

Example: Chunks get synced at 10:12:26.523 and desync right after. Why? We are not quite sure yet.
What’s Next
Right now the sync algorithm is very simple and based on two numbers: sync interval and minimum utilization.

Even with this basic idea, we can see nice benefits already. For logs stored from one of our clusters in a two-hour period at the beginning of February, we can see storage use decrease to about 1.2x of what’s required (previously closer to 3x), with 160 percent time overlap between chunks on average (again, previously 300 percent).
It is possible that a slightly more complex algorithm that would adjust these two numbers per series would fix problems with both busy and idle series. However, since this check runs for every log line ingested by Loki, it also needs to be fast and not use too much data per series. If you have ideas, we would love to hear them!

