
\[KubeCon Recap\] Cloud Native Architecture: Monoliths or Microservices?
Microservices have been gaining popularity since they were introduced in 2015. But they come with challenges for both developers and users because of the intricate configuration and deployment which often leave developers longing for the simplicity of monolithic applications.
In a talk at KubeCon + CloudNativeCon last month, Grafana Labs software engineers Goutham Veeramachaneni (who is a maintainer on the open source projects Prometheus, Loki, and Cortex) and Edward Welch (who is the Loki tech lead and also works with Cortex) propose a solution that’s part monolith and part microservice. They dubbed it a monomicrolith, “which we just trademarked a couple of minutes ago,” Welch joked at the start of the session.
History of Monoliths
To illustrate why monoliths are “the greatest thing ever,” Welch used the example of launching a pet-walking service and creating a basic proof of concept with a website and backend in one repo. “We continued the journey onto our monolith, like the way most applications would start,” he said. “It’s easy to develop a single application.”
Deployment of the site was also easy, by putting it on a service with a SQL database and pointing Pingdom and Nagios at it. Monitoring and updates were straightforward too, since high availability wasn’t a concern.
However, as the business grew, and in their example, expanded beyond dogs to walking llamas and charming snakes, the system got more complicated. The monolith kept everything in one repo, but as more people started working on the files at the same time, conflicts would arise. Ansible could scale the deployments, but it was hard to maintain since not everyone kept playbooks updated or ran them to completion – and it just became a game of troubleshooting.
“We had to use sticky sessions on our load balancers in order to do some kind of parallel scaling because our app wasn’t really built to be stateless,” Welch added.
In essence, it fell victim to Conway’s Law, which computer scientist Mel Conway came up with in 1967, stating: “Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.”
That is, as an organization starts adding on business units like sales, marketing, and training, they’re all seeking different needs from the software. “The lines keep getting blurred,” Welch explained. “The application keeps getting bigger and we were really struggling.”
The Scalability of Microservices
In order to meet the newfound needs, the hypothetical dog-walking service sought to move to microservices, which is when Veeramachaneni stepped in and started implementing them with one sole purpose: scale.
“We added millions of users, and one monolith is not able to keep up with the scale of that. We raised a bunch of money so we can have more and bigger instances,” he explained, adding that growth wasn’t just impacting throughput, but organization as well – and the single code base couldn’t keep up with that. “We were trying to release every week, so we cut a release on Monday, and by Wednesday the snake charmers couldn’t snake charm anymore, so we had to roll it back. Everyone was trying to get their features in. Nobody was trying to test their features and everyone was blaming everyone else. It was just getting super untenable.”
So Veeramachaneni came in and split the architecture into separate microservices for each team. Channeling Oprah Winfrey, he said: “You get a microservice! You get a microservice!”
That allowed everyone to stay in their own lane, but soon there were too many microservices, he explained, pulling up a tweet from Monzo backend and platform engineer Suhail Patel, showing more than 1,500 simultaneous microservices running, which Veeramachaneni said is “insane and awesome.”
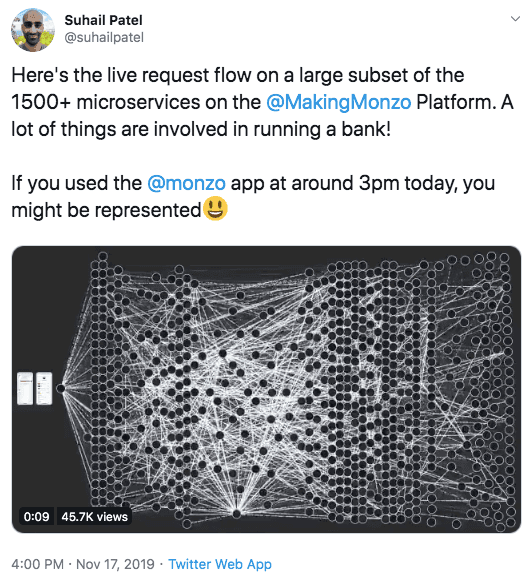
But in reality, that can be simply too much.
When Veeramachaneni first joined Grafana Labs, he was working on a hosted Prometheus CNCF project called Cortex, which used about seven or eight microservices – a far more manageable amount.

While it started with run-make-test scenarios, it grew to running Kubernetes with Minikube through each application using an Up query. Soon the queries started slowing down and generating too much information, increasing the urge to go back to monoliths where all the logs were in one place.
Just as he was growing frustrated, he came across a blog post by Segment called “Goodbye Microservices: From 100s of problem children to 1 superstar.”
“I was like, yes, this makes so much sense,” he said. “And then I noticed the rise of the Monomicroliths or Micromonoliths. So I think that these applications are the future.”
What is a Monomicrolith?
“A monomicrolith is a single binary monolith composed of microservices,” Veeramachaneni defined, giving the example of the CNCF project Thanos, a single binary system similar to Prometheus but with other tradeoffs.
He put the Prometheuses in three different clusters and then added on a querier service to talk to the sidecar and the different Prometheus servers. Then, to add on long-term storage, he added on an object storage layer to upload the blocks into storage – and finally added on the compactor layer to create bigger blocks.

“The thing I really like about this is that it gives you incremental value,” Veeramachaneni said. “You can start with something super simple that you understand and then you can add one more component, and you can come up with a much more complex architecture.” That also allows troubleshooting to be easier since it was grown from the ground up: “You gain confidence and then went to something more complex, which is amazing.”
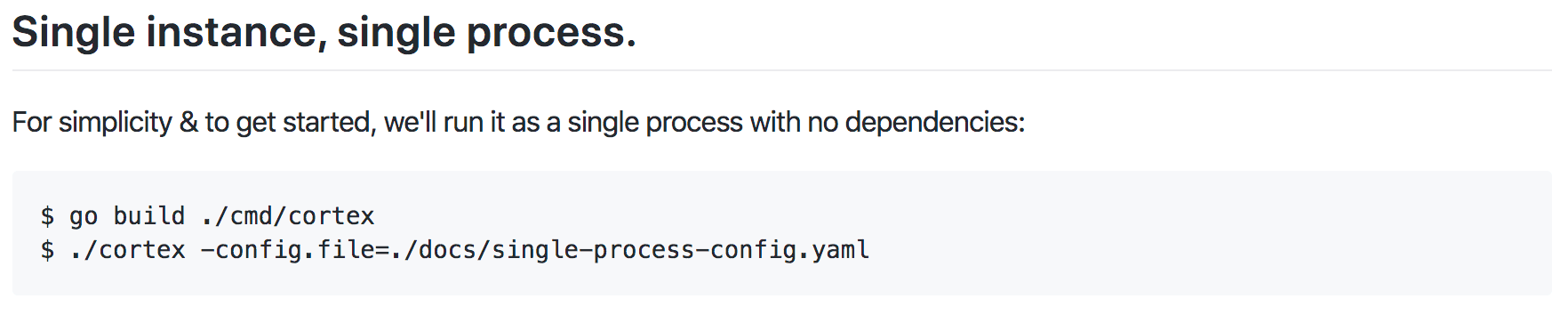
They were able to also do the same thing with Loki on just one binary and then revisited Cortex and architected it again to be just as simple, as seen in the single instance and process (shown below) run locally – without the need to use Kubernetes. Later, after pushing it to dev in a bigger Kubernetes cluster, it could be tested at scale.
The strategy of scaling incrementally as a monomicrolith can be applied not just to Cortex, Thanos, and Loki, but to Jaeger and Elastic as well. “These are really good applications that have seen incredible adoption because they are monomicroliths,” he said.
How to Build a Monomicrolith
Modules
To understand the advantages, Welch took a step back for a more high-level view to see what core components made the functionality possible – and the first thing he found was the modular code base, a software term that’s been around since the ’60s.
“Building an application that’s modular is not necessarily hard, but knowing where to draw the lines of modularity is,” he said. “One of the things that I think that makes sense in the world of horizontal computing is to build modules around how your application scales.”
For example with Cortex and Loki, modules are built around the read and write paths, allowing them to scale on their own boundaries.
Single Binary
Since monomicroliths are a single binary application that can be scaled horizontally, they’re immediately desirable. “This has seen a huge amount of success because it has a really low barrier to entry, but it has a lot of other benefits,” Welch explained. “We’re able to run the application locally from my editor with a debugger.”
This is achieved by combining all the modules under a single executable which is capable of being run by a single command ./cortex. To help achieve this use a composable config object is used(which should map to a config file):

Configuration for each module – such as querier, ingester and storage – can remain in the individual modules. That gets pulled up into the composed config object to allow it to run ./cortex through a single file, simplifying the process overall.
When it comes time to scale the application, the same binary can be configured via command line parameters to only load specific modules of the application and it will then run only as a single part of the application as a whole.
Both Loki and Cortex use a target= parameter to configure the runtime behavior of the binary.
As an example of how this works inside Loki, take a look at the loki.go and modules.go files in the loki package. The target value determines which modules are loaded, with the default of All loading and starting all the modules.
Communication
What enabled the convertibility between a single process and microservices is gRPC, a high-performance, open source universal RPC framework. “When we registered the handlers, essentially the paths for the handlers are separate, even though they’re loaded in a server and localhost. And so when that process runs as a single binary, it effectively makes gRPC calls to itself on localhost,” Welch explained. However, when the same binary is launched with arguments to only load specific modules, that same gRPC infrastructure allows the components to continue to communicate on separate processes and separate machines.
While the single binary using gRPC to call itself may not be the most efficient, it allows for ease of use and simple debugging – plus it runs on what he likens to “airplane mode,” or running the app without internet access. “If you have a dependency on an API or third party, abstract it through an interface and then make a simple implementation of it – something that writes to the file system or that produces data that you can configure – because that really speeds up your ability to develop the app,” Welch said. Plus, when you reach scaling limits of the single binary it’s easy then to convert to microservices using the same binary and same config file.
Monorepo
One other advantage – which he admitted may be more opinion – is the monorepos like Loki, Cortex, and Thanos stuff everything in the same repo. “Keeping that code in the same code base and limiting the effort required to refactor your code base is a big advantage for consistency and tagging,” Welch concluded. “It’s hard to see the advantages of breaking these things up into separate repos.”
Other Considerations
Admittedly, there are still some caveats with this approach. Cortex in particular is very limited with the “airplane mode” version of file storage, the implementation is simple and allows for basic testing/debugging. “It’s better if you point it at a shared cloud storage or local storage like Cassandra, Dynamo, S3, or Bigtable to abstract your storage interfaces,” he said.
But overall, the payoffs are worth it. “You’re making some tradeoffs in how performant it is in one direction or another, but it gives you a lot more flexibility,” Welch said.
“This makes the development process super easy and the adoption process incremental,” Veeramachaneni added. “Once we actually moved a Cortex from a microservices to a monomicrolith world, the number of blog posts, adoption, users and everything shot up – it really makes a difference when you make the development and adoption experience super seamless.”

