

Grafana Labs at KubeCon: Foolproof Kubernetes Dashboards for Sleep-Deprived On Calls
We’ve all been in the situation where suddenly you are the lone developer on call while everyone is out of pocket.
Or in the case of Grafana Labs Director of UX David Kaltschmidt, his then business partner, Grafana Labs VP of Product Tom Wilkie, was checking out for a weekend music fest.
“Tom and I founded a company a couple of years ago, and I’m more of a frontend person. Tom did all the backend and devops stuff,” explained Kaltschimdt. “Then one weekend Tom said, ‘David, I’m going to a heavy metal festival, and you need to watch the servers.’”
“I was freaking out,” he admitted. “An easy on call shift allows for debugging and follow-up such as working on features or reducing toil. But a difficult on call experience puts a developer on the defensive, mostly responding to incidents where every minute counts.”
“I was just hoping that never happened when Tom was in a tent somewhere sleeping,” said Kaltschimdt.
So that no one loses sleep over on calls ever again, Kaltschmidt shared his tips and tricks for creating foolproof Kubernetes dashboards at KubeCon 2019.
Being on call in the context of Kubernetes is, at first, “mind-boggling,” said Kaltschmidt. “The process is so difficult because you have to do the troubleshooting across a couple of dimensions and all the concepts in Kubernetes.”
And troubleshooting is as much about finding the issue as it is about eliminating potential situations where the issue is not, said Kaltschimdt.
To help, Kaltschmidt introduced the Dashboarding Maturity Model (DMM), a three-tiered approach that will help align teams and make dashboards more consistent within organizations. Also DMM will give individual engineers some guidance along their dashboarding journey – and show them how to take it to the next level.

Low Maturity
Here are three signs of low maturity dashboarding, which indicate there is no effective strategy in place.
Sprawl: This is when duplicating dashboards goes unmanaged and gets unwieldy. “Grafana makes it really easy to modify dashboards,” said Kaltschmidt. But it’s easy to leave the “copy tags” function on.
“You probably had good intentions using it. But then someone else came along, cloned the dashboard, left copy tags on, but modified something that semantically represented one of your tags,” said Kaltschmidt. “Those dashboards diverge, and if you later use those tags to find your things, you end up with a long set of dashboards that are no longer representing what the tag originally meant.”
No Version Control: What happens when you modify a dashboard and you hit save without version control? “If you have a standard Grafana instance and you don’t back up your data or you don’t have your dashboard JSON in version control and your Grafana goes away, then you’re going to have a bad time,” he said.
Browsing for Dashboards: A similar behavior that’s symptomatic of low maturity is browsing for dashboards. “If you find yourself browsing a lot – going through folders and going back and forth to find the right thing – that’s the sort of behavior a mature user wants to get away from,” said Kaltschimdt.
Medium Maturity
Here are some Grafana-approved methods to managing your monitoring dashboards.
Templated Variables: A dashboard for each node in Kubernetes isn’t necessary because factors that are tracked, such as CPU usage or usage per core, appear in the same panel layout for all the nodes.
Within Grafana, the nodes can be registered as template variables, and users can access a dropdown to look through all their instances. “If you’re really clever,” said Kaltschimdt, “you can do this for various data sources as a higher level template variable. Then you can basically access a lot of different clusters.”
Methodical Dashboards: There are a couple of dashboarding methods that help make sense of what could go wrong in Kubernetes along various dimensions.
For services, the RED method measures request and error rate as well as duration for each service. Check out Tom Wilkie’s overview of this method.
For resources, the USE method measures utilization, saturation, and errors. In the example below, these dashboards are part of the Kubernetes monitoring mixin.
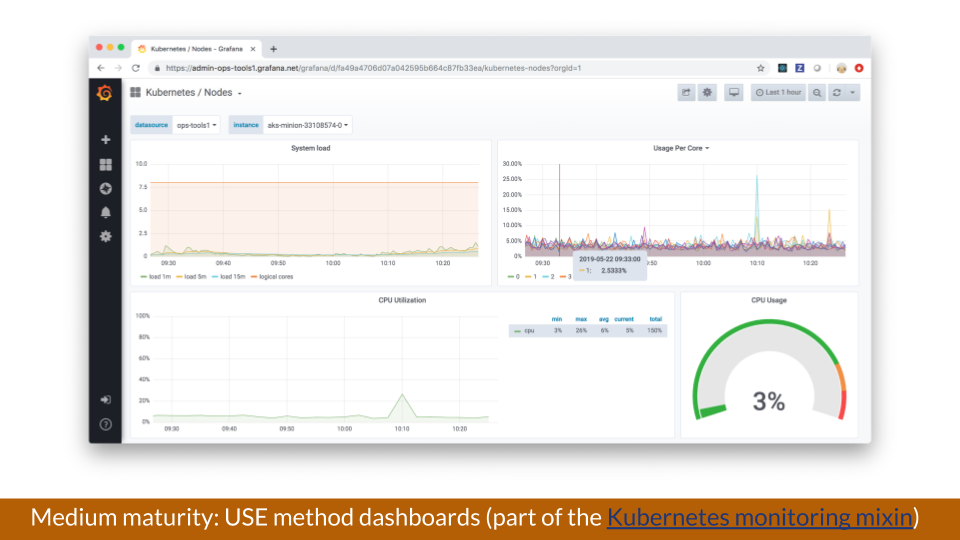
Above is a view of what a node represents and also what problems a node can have.
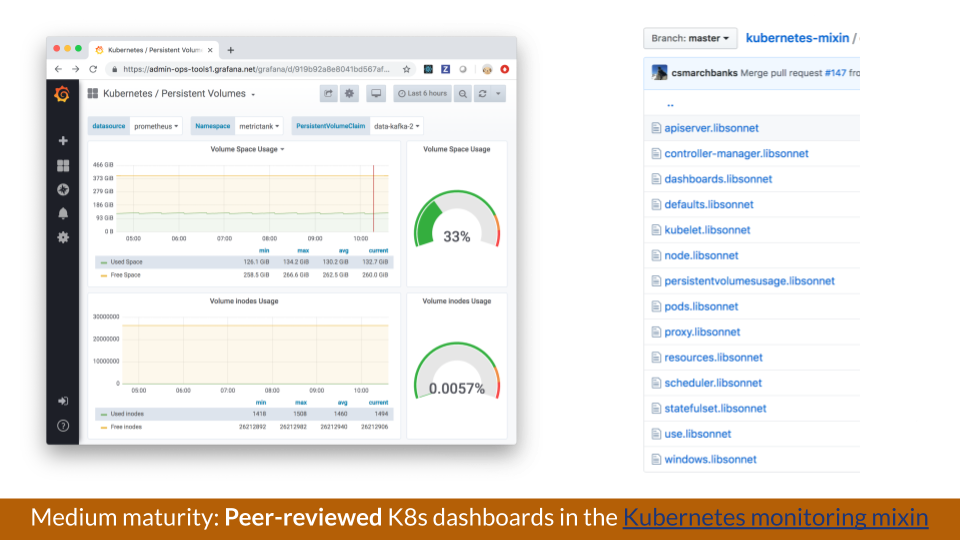
Above is a set of dashboards in this repo about persistent volumes that also shows various other dashboards that are available.
Hierarchical Dashboards: This type of dashboarding method does a great job at providing summary views with aggregate queries by using the power of trees or the logarithmic drilldown to pinpoint where a problem is.
“They really help in the elimination process. You can quickly see in the higher level tree dashboards that things are okay so you can move on to the next one,” explained Kaltschimdt.

One hierarchy example would be cluster, namespace, and pod. All of these queries will have to be structured in a way that whatever is below or whatever is above, aggregates those metrics in a meaningful way. But then the question becomes how do you navigate between them?

At Grafana, there would be a cluster view broken down by namespaces. The breakdown in these queries will always be the next level down so you can move into the next level by using one of these drilldown links in the table. This is also part of the Kubernetes monitoring mixin.
Service Hierarchies: Using the same dashboard, you can see how data flows through an application.
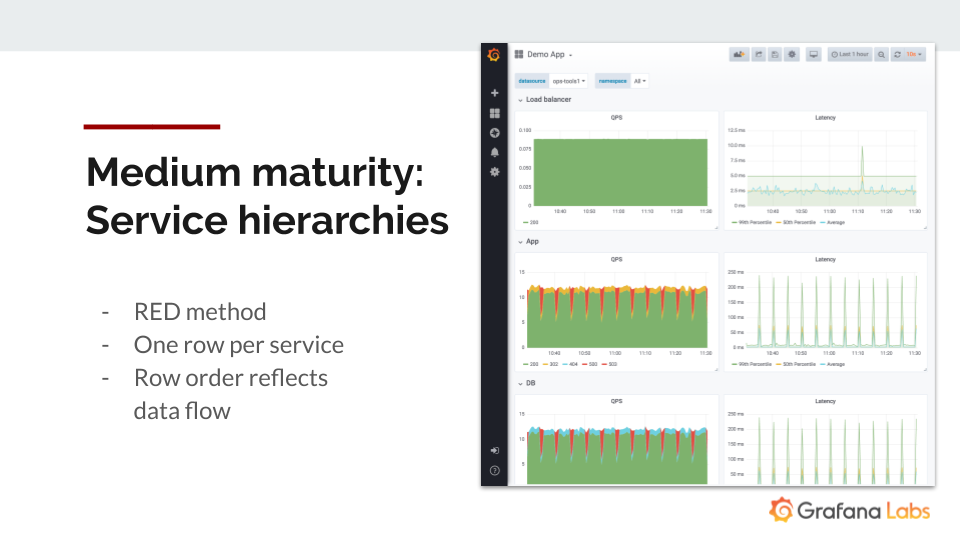
Here is the RED method using one row per service, with the request rate and error rate on the left and the duration of the latency on the right.
“The really powerful thing here is that you can see at the top, which is the local answer that tracks the responses to the user, that the user is not going to see any errors because there’s nothing red. But there’s obviously something wrong because the lower dashboards have red,” explained Kaltschimdt.
“If we’re looking at the app, there’s some red there. We know that the app relies on data from the database, and by virtue of the database also being red, we get a hunch that the error may be in the database,” he said. “So this vertical hierarchy inherently leads me towards a hunch about where the system is not working.”
Expressive Dashboards: “One thing to keep in mind is that sometimes it’s worth splitting up a service or an app into two different dashboards, mainly because the magnitude can differ,” advised Kaltschmidt.
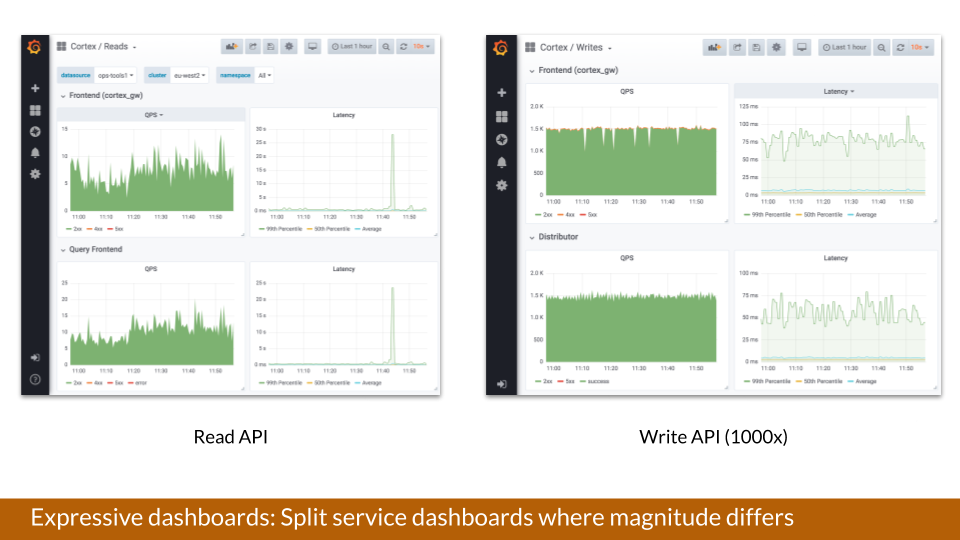
For example, Grafana is on Cortex, which is a Prometheus-based service, and a lot of data is being consumed. “If it’s always at a magnitude like 1000x, any errors in the read path would be drowned visually if they were in the same dashboard and those metrics were aggregated,” said Kaltschmidt.
Expressive Charts: One tip for making your dashboards “really expressive” is to use color to give you a quick hint about what’s going on, said Kaltschmidt.
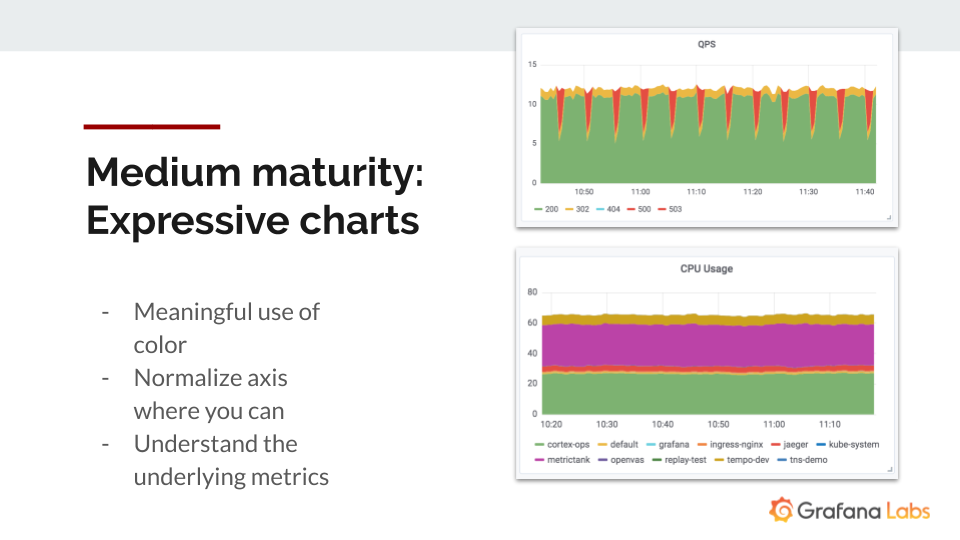
In the top diagram, with only 200-s in green and 500-s in red, “this helps quickly draw a conclusion on the state of this app,” said Kaltschmidt.
Kaltschmidt also advised to normalize graphs by the Y axis “so you instantly get a feel for how busy something is.” This is especially useful for dashboards that track a situation where the resource is bound, like CPU.
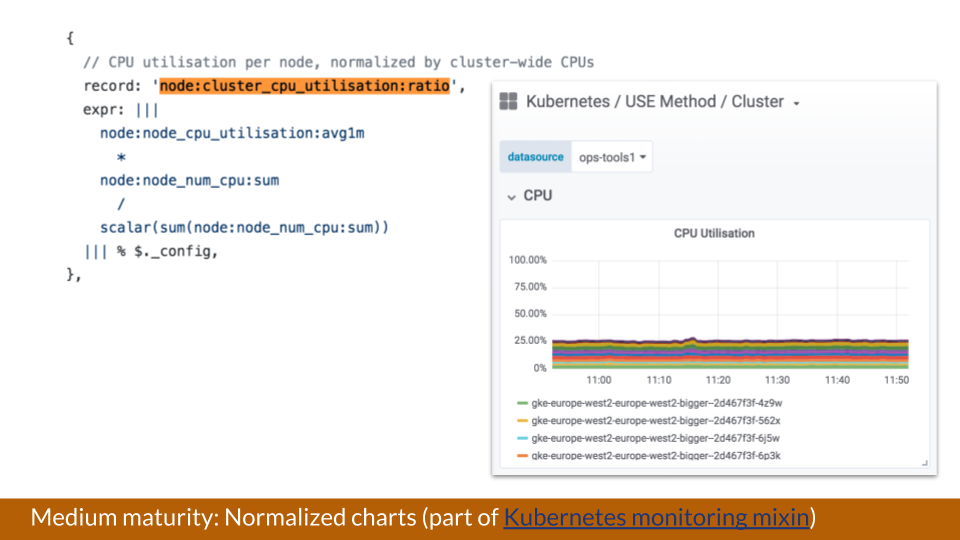
Taking another example from the Kubernetes monitoring mixin, above is a cluster and each of these lines represents a node. But it’s unclear how many CPUs the nodes have because there could be provisions of different sizes.
“If we normalize this by the CPU count or across the cluster, we can definitely say a lot of resources across the cluster are being used leading up to 100 percent,” pointed out Kaltschmidt. “This is really powerful because you reduce the cognitive load of having to draw conclusions on how much space is left.”
Directed Browsing: While template variables make it hard to navigate or “just browse” through the dashboards, that’s a good thing.
“You actually shouldn’t just navigate through them, especially if you have three-level hierarchies,” said Kaltschmidt. “That will actually encourage you to use alerts.”
Managing Dashboards: Lastly, where should we store the dashboard code themselves? “There’s a couple of initiatives inside Grafana going on, and the most important revolves around improving the provisioning workflow,” said Kaltschmidt.
Any developer interested in this, check out the Grafana design doc or go to Issue #13823 on Github and comment.
High Maturity
Sometimes in devops organizations, people know good practices, but they still deviate from them. Here are ways to achieve consistency by design.
Scripting Libraries: Scripting libraries such as grafonnet (Jsonnet) and grafanalib (Python) give you higher order functions to generate certain types of dashboards, said Kaltschmidt.
“The important thing is that those functions can encode, for example, a query panel,” he said. “If you use this function, you can ensure that all the rows and all the dashboards that have been created will share the same style. There’s no longer a fight of should we use line fills or not … and you guarantee across the organization that your dashboard panels are similar enough so that people can find their answers quickly.”
One of the biggest benefits of scripting libraries are the smaller change sets. “If you use higher-order functions, you don’t have to deal with this massive JSON anymore because you only need to compare the query change.”
Mixins or Other Peer-Reviewed Templates: Mixins are a set of dashboards and alerts that are peer-reviewed and a great resource for any organization.
“The mixins I’ve been showing have been written in Jsonnet, but you can still extract the queries and use them in your own dashboarding journey. It’s a really good resource to look at how people monitor Kubernetes using Prometheus,” said Kaltschmidt.
For more information on Kubernetes mixins, check out this blog post.
Future Tools to Help
Grafana is looking to improve its workflow so that in the browser, there will be an editor to live edit JSON. “But that’s a bit in the future,” said Kaltschmidt.
Until then, “it’s good to have a strategy for dashboarding. Start with the goal of managing the use of methodical dashboards. Then the next step can be consistency by design,” said Kaltshcmidt.
But always remember: “Your dashboarding practices should reduce cognitive load – not add to it.”


