

Make time-series exploration easier with the PostgreSQL/TimescaleDB query editor
By Timescale’s Sven Klemm and Diana Hsieh

Grafana v5.3 comes with a new visual query editor for the PostgreSQL datasource. The query editor makes it easier for users to explore time-series data by improving the discoverability of data stored in PostgreSQL. Users can use drop-down menus to formulate their queries with valid selections and macros to express time-series specific functionalities, all without a deep knowledge of the database schema or the SQL language. Prior to Grafana v5.3, users had to handwrite SQL queries in order to query data. By combining the usability of the query editor with the power of full SQL, users can generate dynamic dashboards and visualizations in Grafana.
Both the query editor and PostgreSQL datasource are contributions made by TimescaleDB engineers to the open-source Grafana community. In this blog post, we will cover why we decided to build a first-class integration with Grafana for PostgreSQL (and TimescaleDB) and provide an overview of the new capabilities now possible with the query editor.
Building an open-source visualization stack
TimescaleDB is an open-source time-series database powered by PostgreSQL. We leverage the extensibility of PostgreSQL to provide a database that scales for time-series data without sacrificing the flexibility and expressiveness of relational databases. Our users typically range across a wide variety of use cases including IoT, DevOps, and web applications. Through our interactions with our users, we came to realize that users with time-series needs also consistently had visualization needs, regardless of the industry they were in. The nature of these visualizations were often different - some were powering custom visualization dashboards surfaced to end users, while others were hooking visualization tools into their TimescaleDB instances in order to analyze and share operational data internally.
Within the DevOps monitoring use case specifically, TimescaleDB is a compelling option for storing long-term metrics since it can handle complex data schemas and queries. We discovered that DBAs and SREs who chose to store metrics in TimescaleDB quickly found that they could run more interesting analyses using full SQL and that those insights would be valuable across the entire organization (e.g., for resource allocation, capacity planning, internal billing / cost accounting). They wanted to share these insights using dynamic dashboards that different business units could access.
This story is ultimately what inspired us to invest time in adding TimescaleDB compatibility to the existing PostgreSQL datasource, as well as building the PostgreSQL query editor for Grafana. We noticed that Grafana was quickly becoming the de facto visualizer of choice for the monitoring use case. As big supporters of open-source software and being an open-source solution ourselves, we view our contributions to Grafana as a continued commitment to developing a vibrant open-source community.
Using the Grafana Query Editor for PostgreSQL
The PostgreSQL query editor provides an enhanced user experience for Grafana users connecting to PostgreSQL as a datasource. It features a template that users can use to build SQL queries, as well as context aware suggestions for table names and columns. Ultimately, the query editor makes it easier for users who are not intimately familiar with the database schema to explore columns and values.
Structuring a query to identify trends over time
In Grafana v5.3, you’ll notice the new query editor when you edit an existing datasource or create a new PostgreSQL datasource. Upon building a new graph, the query editor will jumpstart the editor with a valid example query (if one exists). You can then leverage this example and edit it to fit your needs.
A good place to get started with the query editor is to build a simple query that graphs a time series. In the below image, the query editor has selected the cpu_utilization time-series from the devops table. The $__timeFilter macro generates queries that fill in the dates from the time selector on the top right, thus allowing dynamic visualizations based on time ranges.
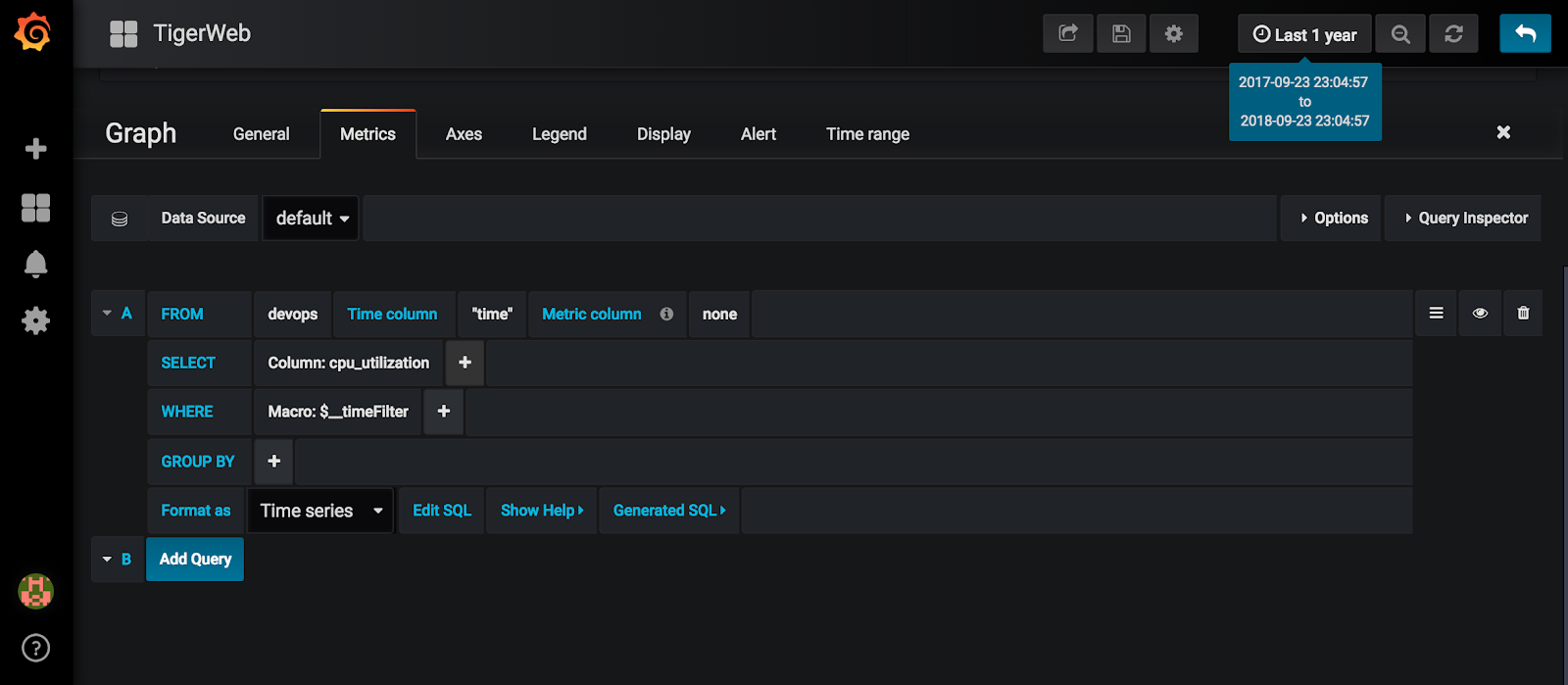
Identifying trends utilizing aggregation functions
When graphing time-series, it is sometimes useful to aggregate data into time buckets. These aggregations can help identify trends over time by grouping raw data into higher level aggregates. For example, you might want to average monthly raw data daily to achieve a smoother trend line or count the number of occurrences of non-numeric data.
The below video demonstrates how you can modify the above example query using aggregate functions to achieve a smoother trend line that groups data collected over the entire year into daily buckets. One thing to note is that the $__interval option in the time() function is a special variable that changes based on your selected time range. If you are collecting a lot of data, make sure you consider how many data points you are pulling in when running these queries.
Alternatively, you might have data that is not numeric in nature. In the below query, we update the example query to pull from a different table that contains usage metrics. However, usage metrics are stored as a string type where different user requests are stored as different string values. In this example, we want to count the number of times any user signs up over time.
Using window functions to apply calculations over windows of time
The query editor also supports window functions including increase, rate, sum, and moving average. In the below example, we have taken the previous example and augmented it with the increase() window function. This is a utility function that makes it easier to represent increases over windows of time versus writing a formula to calculate it in plain SQL. The function takes the time bucket specified in the GROUP BY clause and calculates the increase of the metric we are graphing over that specified window. We’ve shown both how the window function can calculate increase() over the 24 hour period, as well as how the window function updates when we change the time period to 10 minutes.
Combining SQL with the query editor to form complex queries
In addition to the visual query editor, Grafana continues to support writing raw SQL queries. You can use the query generated by the query editor as a jumping board for adjusting raw SQL. Using SQL, you can utilize JOINs to correlate time series data with relational metadata or other time series data.
In the below example, we show how you can use a JOIN to augment the usage metrics query with relational metadata. In this example, we group user signups by country. However, the country that a user comes from is stored in a separate relational table. By joining the two datasets, you can now filter the time series results by the appropriate relational metadata.
Leveraging TimescaleDB’s built-in functions
Although both the query editor and SQL editor interface work with PostgreSQL, they will also utilize time-series specific functions when TimescaleDB is enabled in Grafana and properly installed with PostgreSQL. You can utilize these functions to manipulate time-series more easily. In the below example, we show how the $__timeGroup macro automatically generates a query that utilizes the TimescaleDB function time_bucket(). You can then use the time_bucket() function to group data by arbitrary time periods by simply changing the bucket parameter. Other TimescaleDB functions work as well, and you can explore the options here.
Filling in gaps in data with the gap filling functionality
Depending on the types of graphs you want to display, sometimes you may want to fill in gaps in data. In the below example, we’ve zoomed in on the CPU utilization query to display more granular CPU utilization metrics in the form of a bar chart. You will notice a lot of gaps in the data, which result in empty spaces in the bar chart. The time() function in the GROUP BY clause includes two parameters: the first specifies the time interval in which to bucket time series, while the second specifies what value to fill the gaps with. This function uses the $__timeGroup() macro which you may also use in raw SQL queries, where the 3rd argument is the fill mode. In the below example, we’ve selected previous, which fills in gaps with the previous observed value. As a caveat, the previous value will not be pulled if it is not in the time range selected. You can observe this phenomenon in the example below as well. It’s important to note that if you build a stacked graph, you will also need to utilize this gap filling functionality so that the stacking renders properly.
Sharing configurable dashboards across your organization
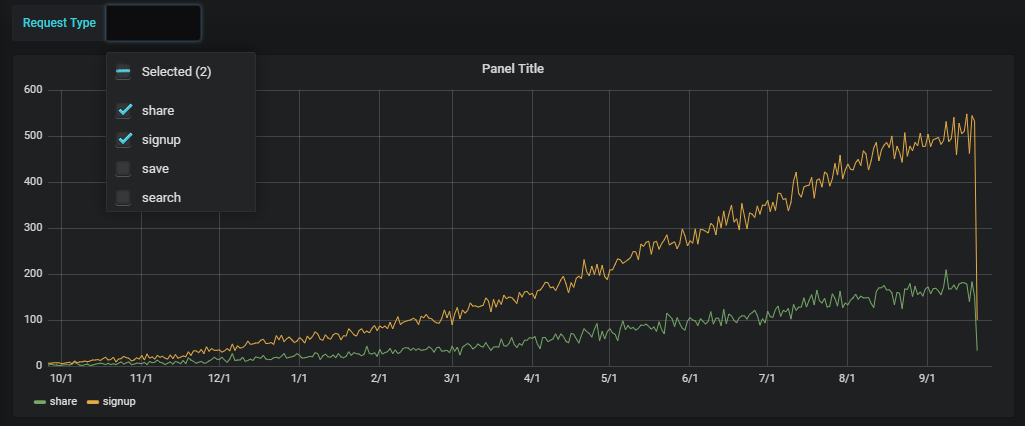
Grafana comes with the ability to define template variables that can power drop-down selections. In the below example, we’ve created a template variable that pulls in the values of the request_type column. This template variable appears as a drop-down menu in the top left. We inserted the request_type variable in the WHERE clause of our query, thus allowing Grafana to populate the WHERE clause dynamically with the value selected from the drop-down menu. You could share this dashboard of user request types with your business organization, allowing them to filter the results based on the request types they are most interested in without changing the Grafana query itself.
Next Steps
In summary, we have shared both the rationale for contributing PostgreSQL/TimescaleDB integrations to Grafana, as well as specific examples of how the new query editor makes it easier to build dashboards in Grafana. Both Grafana and TimescaleDB are available to download for free as open-source software, and we would love for you to try both out and let us know what you think.
If you’re ready to get started, please download TimescaleDB (installation instructions) and Grafana (installation instructions).
For more information about the new query editor, check out the recent Grafana v5.3 release notes and learn more from their website. To read more about TimescaleDB, check out our website, documentation, and GitHub. If you are interested in learning about time-series data management and analytics, register for our webinar on October 23, 2018. We are also sponsoring GrafanaCon LA in February, so hope to see you there!


